
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- re-id
- github
- REDIS
- vscode
- 미니프로젝트
- 채팅
- WebSocket
- Git
- 1주차
- channels
- js
- 파이썬
- sql
- Class
- 장고
- poetry
- 프로젝트
- 마스킹
- WHERE절
- 알고리즘
- 개발일지
- resnet50
- WIL
- 정보처리기사
- 프로그래머스
- 백준
- 2주차
- Commpot
- 가상환경
- 정보처리기사실기
- Today
- Total
개발일기
[정보처리기사 실기 이론정리10] 데이터베이스(2) & SQL 본문
1. 관계 데이터 모델 : 데이터의 논리적 구조를 테이블 형태로 표현하는 모델. 각 테이블은 튜플(행), 속성(열)로 구성
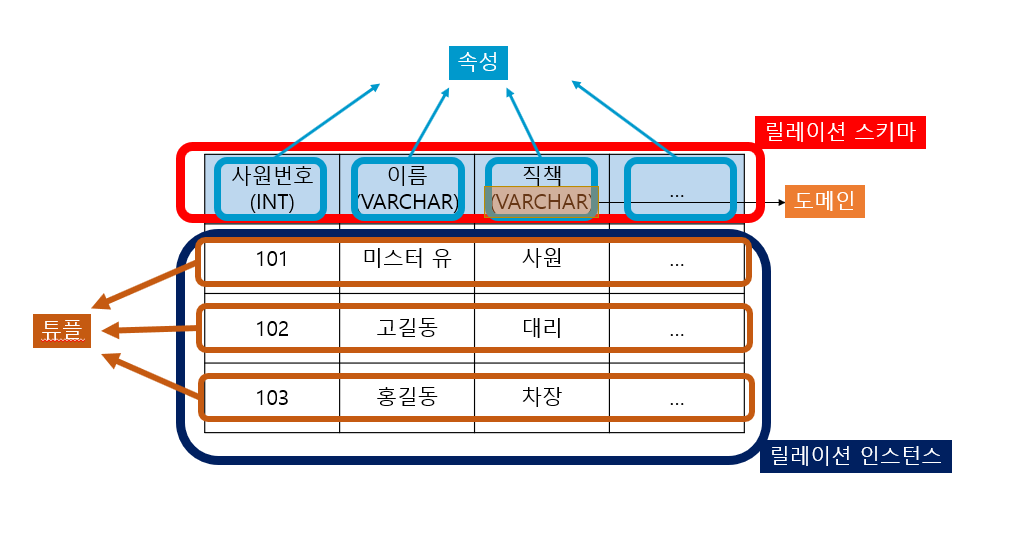
- 속성 : 릴레이션의 열, 개체의 특성을 기술
- 튜플 : 행, 속성들의 모임
- 도메인 : 속성이 가질 수 있는 값의 범위, 데이터 무결성 유지
- 차수(Degree) : 릴레이션에서 속성의 총 개수
- 카디널리티(Cardinality) : 릴레이션에서 튜플의 총 개수
2. 관계대수 : 원하는 데이터를 찾기 위한 절차적 언어
3. 순수 관계 연산자

4. 일반 집합 연산자
- 합집합 : 두 릴레이션의 튜플 합집합을 구하며, 중복 튜플은 제거한다.
- 교집합 : 두 릴레이션의 튜플 교집합
- 차집합 : 한 릴레이션의 튜플에서 다른 릴레이션의 튜플을 제거한다.
- 교차곱(Cartesian Product) : 두 릴레이션의 모든 튜플 조합을 구한다.
5. 관계 해석 : 원하는 정보가 무엇이라는 것만 정의하는 비절차적 특성
| 연산자 | V | OR 연산 |
| ∧ | And 연산 | |
| ㄱ | Not 연산 | |
| 정량자 | ∀ | 모든 가능한 튜플 "For All" |
| ∃ | 어떤 튜플 하나라도 존재 |
6. 키 : 데이터베이스에서 튜플을 식별하고 구별하는 데 사용되는 컬럼
- 후보키 : 릴레이션에서 튜플을 유일하게 식별할 수 있는 속성들의 집합, 유일성과 최소성을 만족
- 기본키 : 후보키 중에서 선택한 주 키(Main Key), 특정 튜플을 유일하게 식별할 수 있으며, NULL값을 가질 수 없고, 중복된 값을 가질 수 없다.
- 대체키 : 둘 이상의 후보키가 있을 때, 기본키로 선택되지 않은 나머지 키
- 슈퍼키 : 튜플을 유일하게 식별할 수 있는 속성들의 집합이지만, 최소성은 만족시키지 않는다.
- 외래키 : 다른 릴레이션의 기본키를 참조하는속성, 참조 무결성 조건을 만족
7. 데이터베이스 무결성 : 데이터의 정확성, 일관성 및 유효성을 보장하는 데이터베이스 관리 시스템의 중요한 기능
- 개체 무결성 : 모든 릴레이션은 중복되지 않는 고유한 값인 기본키를 가져야 한다. 기본키는 NULL값을 가질 수 없다.
- 참조 무결성 : 외래키는 NULL이거나 유효한 참조 릴레이션의 기본키와 일치해야 한다.
- 참조 무결성 제약 조건
- 제한 : 문제의 연산을 거부
- 연쇄 : 참조된 튜플 삭제 시, 참조하는 튜플도 함께 삭제
- 널값 : 참조된 튜플 삭제 시, 참조하는 튜플의 외래키를 NULL로 설정
- 기본값 : NULL 대신 기본값을 등록 - 도메인 무결성 : 모든 속성 값은 정의된 도메인에 속해야 한다.
- 고유 무결성 : 릴레이션의 특정 속성 값은 서로 달라야 한다.
- 키 무결성 : 각 릴레이션은 적어도 하나의 키를 가져야 한다.
- 릴레이션 무결성 : 삽입, 삭제, 갱신 등의 연산은 릴레이션의 무결성을 해치지 않도록 수행되어야 한다.
8. 옵티마이저 : SQL 문에 대한 최적의 실행 방법을 결정
- 규칙 기반 옵티마이저 : 규칙(우선순위)를 가지고 실행 계획을 생성
- 비용 기반 옵티마이저 : 필요한 비용이 가장 적은 실행계획을 선택
9. 튜닝 : SQL 문을 최적화하여 시스템의 처리량과 응답속도를 개선
10. Row Migration : 데이터가 수정되면서 데이터가 더 커져서 기존 블록에 못 들어가는 경우, 다른 블록에 데이터를 넣고, 기존 블록에는 링크를 남긴다.
11. Row Chaining : 컬럼이 너무 길어서 DB BLOCK 사이즈보다 길어진 경우 블록 두 개에 이어서 한 Row가 저장
12. 분산 데이터베이스 : 여러 곳에 분산된 데이터베이스를 하나의 논리적인 시스템처럼 사용할 수 있는 데이터베이스
- 테이블 위치 분산
- 테이블 분할 분산
- 수평 분할 : 특정 칼럼의 값을 기준으로 로우를 분리, 컬럼은 분리되지 않음
- 수직 분할 : 칼럼을 기준으로 컬럼을 분리 - 테이블 복제 분산 : 동일한 테이블을 다른 지역이나 서버에서 동시에 생성
- 부분복제 : 테이블 일부의 내용만 다른 지역이나 서버에 복제
- 광역복제 : 테이블의 내용을 각 지역이나 서버에 복제 - 테이블 요약 분산 : 지역 간 또는 서버 간 데이터가 비슷하지만 서로 다른 유형으로 존재
- 분석요약 : 요약정보를 마스터에 통합하여 다시 전체에 대해서 요약정보를 산출
- 통합요약 : 다른 내용의 정보를 마스터에 통합하여 다시 전체에 대해서 요약 정보를 산출
12. 투명성 조건
- 위치 투명성 : 데이터의 실제 위치를 모르고 논리적 명칭만으로 액세스 가능
- 분할 투명성 : 여러 단편으로 분할된 논리적 테이블 관리
- 지역사상 투명성(Local Mapping) : 지역 DBMS와 물리적 DB 사이의 Mapping 보장
- 중복 투명성 : 동일 데이터의 중복을 사용자에게 숨김
- 병행 투명성(Concurrency) : 다수의 트랜잭션들이 동시에 실행되더라도 서로 영향을 주지 않음
- 장애 투명성(Failure) : 다양한 장애에도 트랜잭션 정확 처리
13. CAP 이론 : 어떤 분산 환경에서도 일관성(C), 가용성(A), 분단 허용성(P) 세가지 속성 중 두가지만 가질 수 있다. 세가지 모두 만족할 수 없다.
- 일관성(Consistency) : 시스템의 모든 노드가 어떤 특정 시점에서 동일한 데이터를 보유하고 있어야 한다.
- 가용성(Availability) : 모든 요청에 대해 시스템이 항상 응답을 해야 한다.
- 분단 허용성(Partition Tolerance) : 네트워크 분할이 발생하더라도 시스템 전체의 작동이 중단되지 않아야 한다.
14. 트랜잭션 : 데이터베이스의 상태를 변화시키는 하나의 논리적 기능을 수행하는 작업 단위
- 원자성(Atomocity) : 트랜잭션 내의 모든 연산은 모두 반영되거나 아니면 전혀 반영되지 않아야 한다.
- 일관성(Consistency) : 트랜잭션의 완료 후 데이터베이스가 일관된상태를 유지해야 한다.
- 독립성(Isolation) : 동시에 실행되는 여러 트랜잭션들은 서로 간섭할 수 없으며, 각각 독립적으로 실행되어야 한다.
- 영속성(Durability) : 트랜잭션이 한번 commit되면 그 결과는 시스템에 고장이 발생해도 영구적으로 반영되어야 한다.
15. SQL : 데이터베이스 시스템에서 데이터를 처리하기 위해서 사용되는 구조적 데이터 질의 언어
- DDL(Data Definition Language) : 데이터 정의어, 테이블이나 다양한 객체들을 정의하는 데 사용
CREATE, ALTER, DROP, RENAME, TRUNCATE - DML(Data Manipulation Language) : 데이터 조작어, 데이터베이스 내의 데이터를 조작하는데 사용
SELECT, INSERT, UPDATE, DELETE - DCL(Data Control Language) : 데이터 제어어, 데이터베이스에 접근하고 사용할 수 있는 권한을 부여하고 회수
GRANT, REVOKE - TCL(Transaction Control Language) : 트랜잭션 제어어, 작업의 단위를 묶어서 그 결과를 단위별로 제어
COMMIT, ROLLBACK, SAVEPOINT
16. 집합 연산자
- UNION : 합집합, 중복된 행은 제거
- UNION ALL : 합집합, 중복된 행도 포함
- INTERSECTION : 교집합
- EXCEPT(MINUS) : 차집합, 중복된 행은 제거
17. JOIN
- 내부 조인(Inner join) : 두 테이블에 공통으로 존재하는 데이터만 추출
- 자연 조인(Natural join) : 동일한 이름과 타입을 가진 컬럼을 기준으로 자동으로 조인
- 전체 외부 조인(Full outer join) : 좌측 및 우측 테이블의 데이터를 모두 포함하고, 중복된 데이터는 하나로 표시
- 왼쪽 외부 조인(Left outer join) : 좌측 테이블을 기준으로 조인하고, 우측 테이블에 일치하는 데이터가 없으면 NULL로 표시
- 오른쪽 외부 조인(Right outer join) : 우측 테이블 기준으로 일치하는 행만 결합하고, 일치하지 않는 부분은 NULL
- 곱집합(Cross join) : 두 테이블 데이터의 모든 조합
18. 저장 프로시저 : 일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합
19. 트리거 : 테이블에 대한 이벤트에 반응해 자동으로 실행되는 작업
'정보처리기사 도전기' 카테고리의 다른 글
| [정보처리기사 실기 이론정리12] 메모리 관리(단편화) & 가상기억장치(페이지 교체 알고리즘) & 프로세스(스케줄링 알고리즘) (0) | 2024.08.07 |
|---|---|
| [정보처리기사 실기 이론정리11] 병행제어 & 운영체제 (0) | 2024.07.27 |
| [정보처리기사 실기 이론정리9] 패키징 & 데이터베이스 (0) | 2024.07.27 |
| [정보처리기사 실기 이론정리8] 테스트 (0) | 2024.07.27 |
| [정보처리기사 실기 이론정리7] 객체 지향 설계 (0) | 2024.07.27 |



