
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬
- 알고리즘
- Git
- 장고
- 채팅
- 2주차
- WHERE절
- 프로젝트
- 정보처리기사
- 마스킹
- Commpot
- js
- WebSocket
- vscode
- REDIS
- re-id
- github
- 정보처리기사실기
- WIL
- 백준
- resnet50
- sql
- 프로그래머스
- Class
- 1주차
- channels
- 미니프로젝트
- 가상환경
- poetry
- 개발일지
- Today
- Total
개발일기
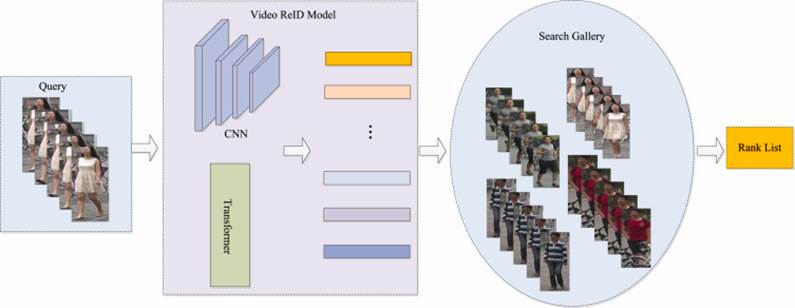
[RE-ID] RE-ID (Re-Identification) 개요 2 본문
RE-ID 모델의 학습은 특징 표현 학습(Feature Representation Learning)과 거리 메트릭 학습 (Distance Metric Learning), 두 방식의 결합으로 구성됩니다.
이 글에서는 RE-ID 모델의 학습 과정 중 특징표현 학습과 거리 메트릭 학습에 대하여 그 내용을 간단히 다루어보겠습니다.
특징 표현 학습(Feature Representation Learning)
특징 표현 학습(Feature Representation Learning)의 모델 아키텍처는 CNN 또는 Transformer를 고려할 수 있습니다.
입력 이미지를 모델에 통과시켜 특징 벡터를 생성하고, 특징 벡터를 통해 모델이 객체의 고유한 특징을 잘 표현하도록 학습합니다.
| CNN | Transformer | |
| 특징 | - 합성곱 연산 - 계층적 특징 학습 - 풀링층 |
- 셀프 어텐션 메커니즘 - 인코더-디코더 구조 - 포지셔널 인코딩 |
| 장점 | - 상대적으로 빠른 학습 속도 - 공간적 정보 유지 |
- 다양한 시나리오에 효과적 - 유연한 입력 처리 |
| 단점 | - 고정된 입력 크기 - 전체 이미지의 구조나 관계를 고려하는데 부족 |
- 높은 계산 비용 - 복잡한 구조 |

CNN은 합성곱 층을 통해 이미지에서 지역적 특징을 추출하고, 필터를 사용하여 이미지의 패턴을 인식합니다.
또한 여러 층을 쌓아가며 낮은 수준의 특징(엣지, 색상 등)부터 높은 수준의 특징(사람의 형태, 복장 등)까지 계층적으로 학습합니다. 풀링 층을 통해 차원을 줄여 계산량을 감소시키고, 중요한 특징을 강조합니다.

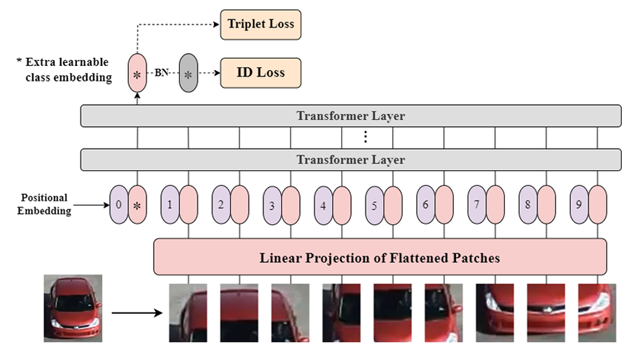
한편, Transformer는 입력의 모든 요소 간의 관계를 동적으로 계산하여 중요도가 높은 부분에 더 많은 가중치를 부여합니다. 이를 통해 전역적 관계를 잘 포착합니다.
인코더-디코더 구조이나 RE-ID에서는 주로 인코더 부분만 사용하여 입력 이미지의 특징을 추출합니다. 또한 입력 벡터에 위치 정보를 더합니다.
거리 메트릭 학습 (Distance Metric Learning)
거리 메트릭 학습(Distance Metric Learning)은 주어진 데이터 포인트 간의 유사성을 학습하여, 같은 클래스의 데이터 포인트는 서로 가깝고 다른 클래스의 데이터 포인트는 멀리 위치하도록 특징 공간을 조정합니다.
CNN 또는 Transformer를 사용하여 이미지에서 추출된 특징 벡터 간의 거리를 계산합니다.
이때 사용되는 거리함수는 유클리드 거리, 코사인 유사도 등을 고려할 수 있습니다. 일반적으로는 유클리드 거리와 코사인 유사도를 사용합니다.
- 유클리드 거리 (Euclidean Distance): 두 점 ( x )와 ( y ) 간의 직선 거리를 나타냅니다. 일반적으로 직관적이며, 많은 상황에서 기본 거리 메트릭으로 사용됩니다.

- 코사인 유사도 (Cosine Similarity): 두 벡터 간의 방향 유사성을 측정합니다. 값이 1에 가까울수록 유사하며, 주로 텍스트 데이터나 고차원 데이터에 사용됩니다.
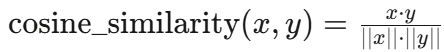
- 하우시안 거리 (Mahalanobis Distance): 데이터의 분포를 고려하여 거리 계산을 수행합니다. 공분산 행렬 ( S )를 사용하여 특성 간의 상관관계를 반영합니다.
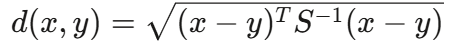
Triplet Loss 또는 Contrastive Loss를 기반으로 손실 값을 계산하여, 손실을 최소화하는 방향으로 모델의 가중치를 업데이트합니다.
Contrastive Loss
Contrastive Loss는 두 개의 입력을 비교하고, 이들의 특징 벡터 간의 거리를 기반으로 손실을 계산합니다.
- Positive Pair: 두 입력이 같은 클래스에 속할 때, 이들의 특징 벡터 간의 거리는 작아야 합니다.
- Negative Pair: 두 입력이 서로 다른 클래스에 속할 때, 이들의 특징 벡터 간의 거리는 커야 합니다.
Contrastive Loss는 유사성과 차별성을 학습하는 데 효과적인 손실 함수로, 같은 ID에 해당하는 이미지에 대한 feature는 거리가 가깝게, 다른 카테고리는 멀게 학습하도록 합니다.

Triplet Loss
Triplet Loss는 RE-ID 시스템에서 가장 핵심이 되는 손실 함수입니다.

Triplet Loss는 anchor, positive, negative 3개를 이용하여 pair를 만들어서 학습하는 방법입니다.
anchor는 기준이 되는 이미지, positive는 anchor 와 같은 카테고리에 속하지만 다른 이미지, negative는 anchor 와 다른 카테고리에 속하는 이미지입니다.
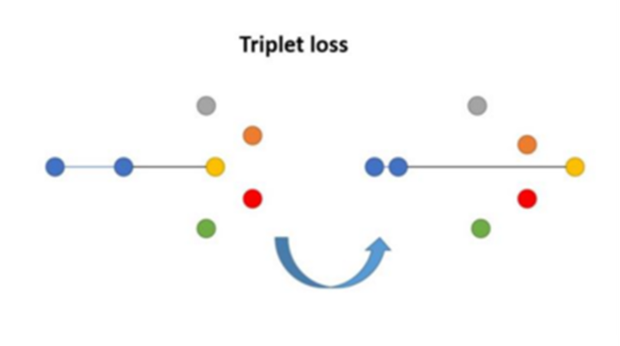
anchor와 positive간 거리는 가깝게 하며 동시에 anchor와 negative간 거리는 멀어지도록 합니다.
[ 거리 메트릭 학습 알고리즘 정리 ]
- Siamese Network :
- 두 개의 입력을 받아 각각의 특징을 추출하는 신경망 구조입니다.
- 이 네트워크는 두 입력 간의 거리를 계산하여, 이 거리를 최소화하거나 최대화하는 방식으로 학습합니다.
- 거리함수는 일반적으로 유클리드 거리나 코사인 유사도가 사용됩니다.
- 이때 손실함수는, Contrastive Loss가 사용되며, 이는 두 입력 간의 거리와 레이블에 기반하여 손실을 계산합니다. - Triplet Loss:
앵커, 포지티브, 네거티브 샘플을 사용하여 객체 간의 거리를 학습하는 방식입니다.
앵커는 기준이 되는 샘플이고, 포지티브는 같은 클래스의 샘플, 네거티브는 다른 클래스의 샘플입니다. - Contrastive Loss:
두 입력 간의 유사성을 기반으로 손실을 계산하여, 유사한 객체는 가까이, 비슷하지 않은 객체는 멀리 배치하도록 학습합니다. 주로 Siamese Network와 함께 사용됩니다.
참고자료
[1] Wang, Hongbo, Jiaying Hou, and Na Chen. “A Survey of Vehicle Re-Identification Based on Deep Learning.” IEEE Access 7 (2019): 172443–172469.
[2] Mang Ye, Jianbing Shen, Gaojie Lin, Tao Xiang, Ling Shao, Steven C. H. Hoi , "Deep Learning for Person Re-identification: A Survey and Outlook" [Submitted on 13 Jan 2020 (v1), last revised 6 Jan 2021 (this version, v2)]
[Paper Review] Deep learning for person re-identification: A survey and outlook
Deep learning for person re-identification: A survey and outlook. Ye, Mang, et al. “Deep learning for person re-identification: A survey and outlook.” arXiv preprint arXiv:2001.04193 (2020).
khyeyoon.github.io
[4] https://github.com/KaiyangZhou/deep-person-reid
GitHub - KaiyangZhou/deep-person-reid: Torchreid: Deep learning person re-identification in PyTorch.
Torchreid: Deep learning person re-identification in PyTorch. - KaiyangZhou/deep-person-reid
github.com
[5] [Overview] Multiple Object Tracking 이란 (2)
[Overview] Multiple Object Tracking 이란 (2)
1. DeepSORT 이전에 올린 글에서, SORT 는 결국 motion 을 기반으로 tracking 하는 방식이라고 설명했다. Kalman Filter 와 IOU cost 만을 사용하기 때문이다. 따라서 두 Track 이 겹칠 때에도 이 2가지만 사용하기
mr-waguwagu.tistory.com
'오늘의 공부일기 > 머신러닝, 딥러닝 공부일기' 카테고리의 다른 글
| RESNET(Residual Network) 개요 (3) | 2025.03.19 |
|---|---|
| OSNET(Omni-Scale Network) 개요 (0) | 2025.03.19 |
| [RE-ID] RE-ID (Re-Identification) 개요 1 (0) | 2025.03.05 |
| [OpenAI] ChatGpt & DALL-E 이용하여 내 맘대로 이미지 만들기 (0) | 2023.05.18 |
| [머신러닝] 지도학습/비지도학습/강화학습 (0) | 2023.05.17 |



